
发布时间:2022-08-04
人工智能在日常生活中随处可见,无论是人脸解锁还是自动驾驶,背后都离不开人脸、车辆、交通标志等物体的自动识别技术。人工智能一旦出错,轻则造成使用者的不便,重则可能引发车毁人亡等严重后果。因此确保算法的安全性是AI研究中非常重要的一部分。目前常见的对抗攻击算法,可以针对人工神经网络进行攻击,通过在图片或语音信息上加入一些难以识别的微小噪声,让AI产生完全错误的判断。
动物和人类在做决定的时候,虽然感官刺激可能存在许多噪声,但是大脑可以排除各种干扰,最终做出合理的选择。认知神经科学中的漂移扩散模型(图1,drift-diffusion model,DDM)定量描述了这个过程:大脑通过积累带有干扰的证据,在达到一定阈值时做出最终决定。大量心理物理实验发现人和动物在抉择过程中的行为能被DDM模型很好的解释。同时,在大脑中的前额叶、后顶叶等脑区均发现了神经元编码并表征了抉择中的证据累积过程。
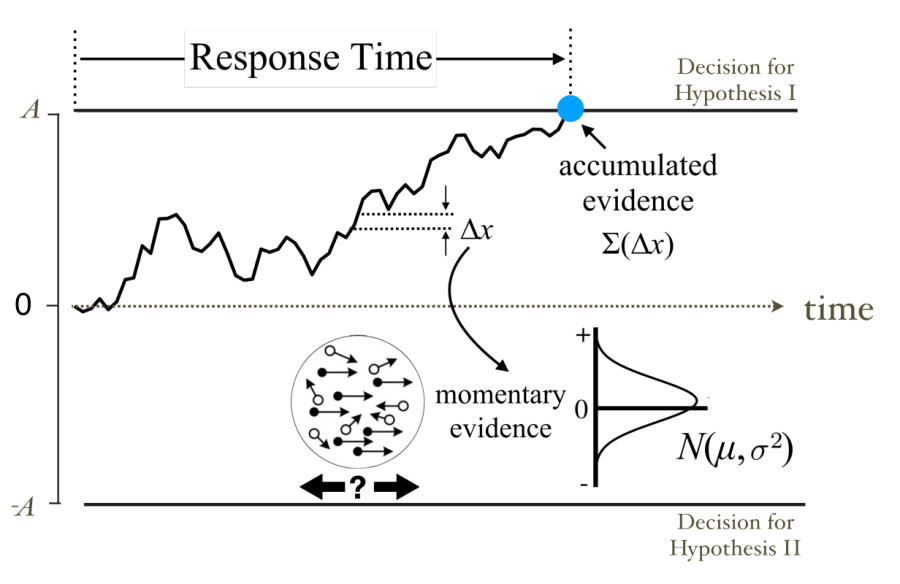
图1:漂移扩散模型示意图。在一个两难选择的任务里,在每个时刻,模型接受到含正态分布的噪声的信号作为证据。模型在时间上进行证据累积,直到累积的证据达到某个预先设定的阈值时候做出相应的选择。
中国科学院脑科学与智能技术卓越创新中心(神经科学研究所)杨天明研究组对DDM模型在大脑中的神经机制进行了长期深入的研究,发现大脑前额叶与后顶叶的神经元在信息累积中所进行的计算原理。受到这一系列研究的启发,杨天明研究组针对人工智能的安全性问题,设计了名为 Dropout-based Drift-Diffusion Model(DDDM)的防御算法(图2)。研究人员首先通过Dropout机制随机失活模型中的单元,来模拟神经元之间的突触噪声,这种人工引入的额外防御性噪声,在AI受到攻击时能够提高被攻击的分类准确率。引入的噪声幅度越大,越能够“覆盖”那些攻击噪声,从而使攻击失效。然而大幅度的噪声也会让AI的输出更加随机,准确率也会随之下降。因此,研究人员进一步引入了DDM机制,把AI对带有随机性的输出作为证据进行累积,并设定阈值进行判断,来去除噪声的干扰,提高分类的准确率。
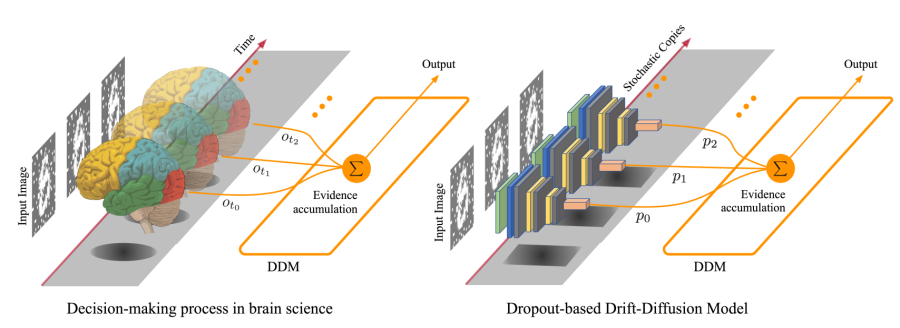
图2:(左)生物脑中的抉择过程。(右)DDDM中的抉择过程。
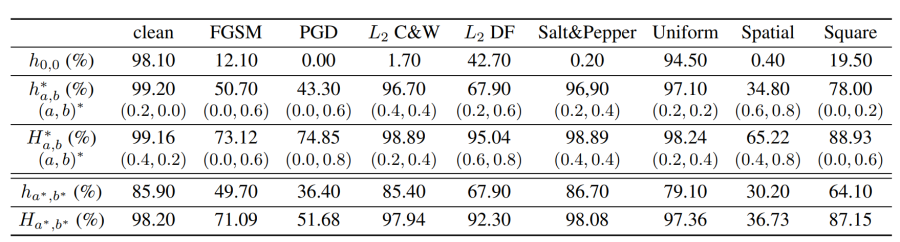
研究人员在图像,音频,文本三种场景下进行了实验,验证了DDDM的在防御攻击时的有效性,不同数据模态和不同攻击方法下的通用性。在最重要的图像分类任务中,研究人员使用了八种不同的方法,去攻击一个手写数字的卷积神经网络分类器。DDDM大幅度恢复了所有攻击下的分类准确率,在四种攻击下的准确率可以恢复到98%以上(表1)。在CIFAR-10图片数据集,IMDB电影评论数据集和SpeechCommands语音指令数据集的实验中,DDDM也成功提高了受攻击后的分类准确率。

DDDM模型还可以动态地对抉择所需的时间进行调整。在攻击噪声幅度逐渐增大时,抉择的难度也变大。这时候,DDDM通过延长决策时间,将分类准确率维持在较高水平。这种行为类似于动物和人类,能够在面对不同难度的抉择时,通过调节做出决定所需的时间来维持一定的准确率。
该研究充分表明,受到大脑抉择机制所启发的DDDM模型是一个在多模态、多任务的场景下能够很好抵御对抗攻击的通用类脑算法框架。模型不依赖于针对特定攻击的预训练,并能够根据需要在时间和精度方面进行取舍。
该研究由博士研究生陈希源,博士后李星宇在杨天明研究员和周熠研究员的指导下完成,已被2022年度国际人工智能联合会议论文(IJCAI-2022)收录。本项工作获得科技部、中科院、上海市的资助。
 附件下载:
附件下载: